
Содержание
Текст Домашнего Задания 5 на английском языке доступен на iTunes в пункте “Programming: Project 5: Smashtag Mentions Popularity″. На русском языке вы можете скачать здесь:
В Задании 5 вы должны еще больше усовершенствовать приложение Smashtag в плане проведения некоторого анализа всех меншенов, полученных в результате поиска в Twitter. Для этого нужно использовать Core Data.
Основными идеями в этом Задании являются получение действующих на различных потоках контекстов NSManagedObjectContext, концептуальное и физическое конструирование схемы базы данных в Xcode, применение различных запросов NSFetchRequest c использованием небольшого встроенного языка для форматирования строк, а также различных дескрипторов сортировки. Необходимо свободно пользоваться классом NSFetchedResultsController или усовершенствованным на его основе классом FetchedResultsTableViewController и расширением extension, созданным Полом Хэгерти специально для этого курса.
Для выполнения Задания 5 нужно посмотреть видео и текстовые материалы Лекции 10 и Лекции 11.
Основой для решения Задания 5 является демонстрационный пример «L11 Smashtag«, код которого доступен как на iTunes название “Lecture 11 Demo Code: Smashtag«, так и на Github.
Код моего решения Задания 5 находится на Github.
Решение дополнительного пункта 3 будет размещено позже.
Будем следовать порядку разработки демонстрационного приложения профессором Полом Хэгерти на Лекции 11.
Cначала я хочу напомнить в общих чертах о приложении Smashtag, на основании которого мы будем выполнять наше Задание 5.
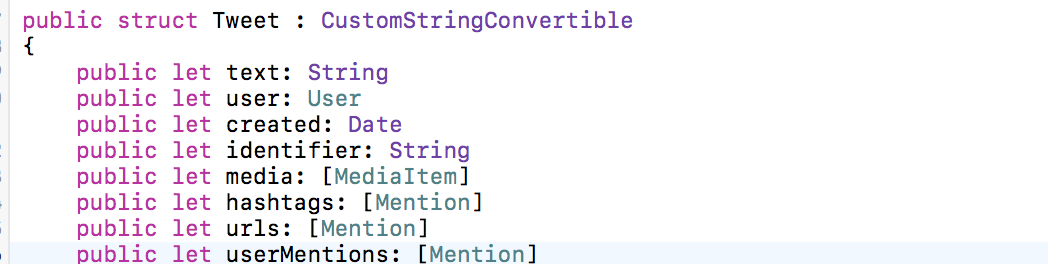
Приложение Smashtag позволяет получить выборку твитов, удовлетворяющих поисковой строке, которую пользователь может задать произвольным образом. Каждый выбранный твит Tweet содержит text, пользователя user, то есть кто твитит, дату создания created, уникальный идентификатор identifier, изображения media, которые подсоединены к твиту, хэштэги hashtags, URLs urls и упомянутые в твите пользователи userMentions:
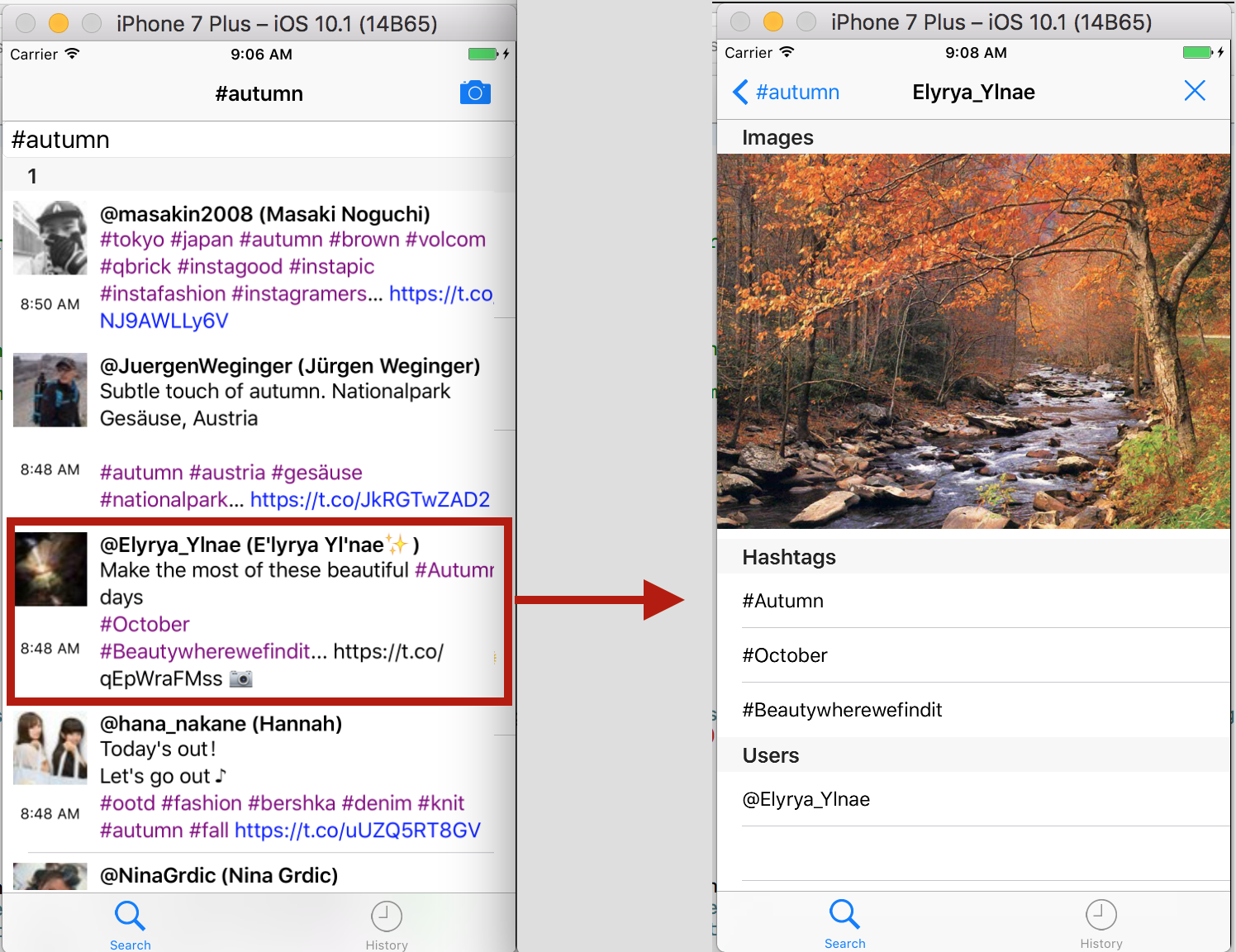
Пользователь задает поисковую строку в виде тэга, в нашем случае #autumn, и получает список твитов, которые содержат этот тэг. Вы можете посмотреть каждый отдельный твит на другом экранном фрагменте, который отображает в виде таблицы с различными секциями все его меншены Mentions: hashtags, urls, userMentions и images:
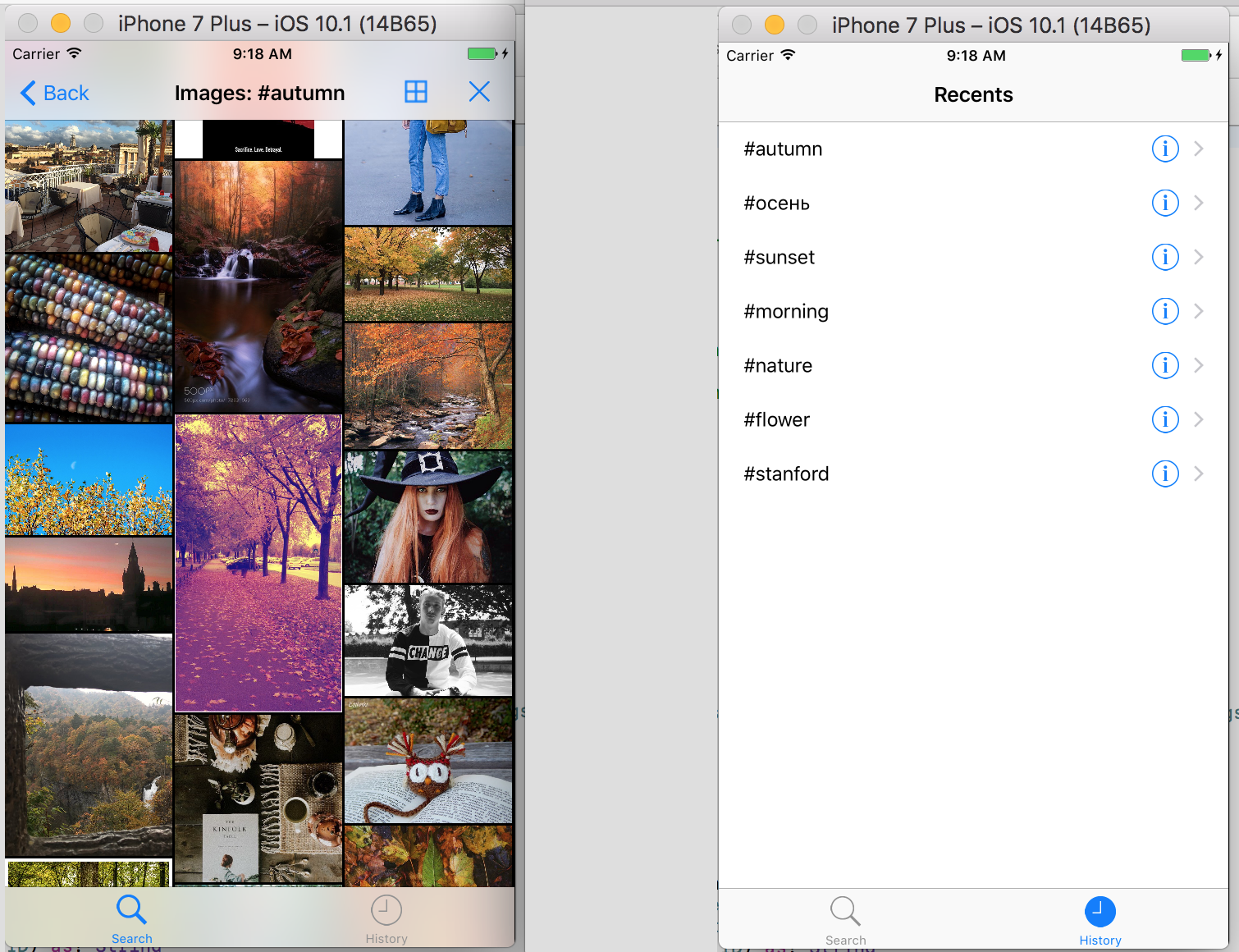
Приложение Smashtag позволяет также посмотреть все изображения в выбранных твитах, а также запомнить строку поиска в NSUserDefauls, чтобы при повторном запуске приложения иметь возможность повторить выборку твитов по старым поисковым строкам.
Задание 5 состоит в том, чтобы наделить маленькую кнопочку с буквой i в кружочке на правом экране следующей функциональностью. Если я нажимаю на эту кнопку, то должны быть показаны все меншены с пользователями (users) и хэштегами (hashtags) во всех твитах, когда-либо выбранных с использованием поисковой строки, для которой мы нажимали кнопку в буквой i в кружочке. Предполагается, что меншены должны быть уникальны и нечувствительны к регистру. Сортировка должна проводится по количеству твитов, в которых этот меншен упоминался, причем наиболее популярные меншены должны располагаться в самом верху. Я сразу покажу готовый результат, чтобы вы понимали поставленную перед нами задачу в Задании 5.
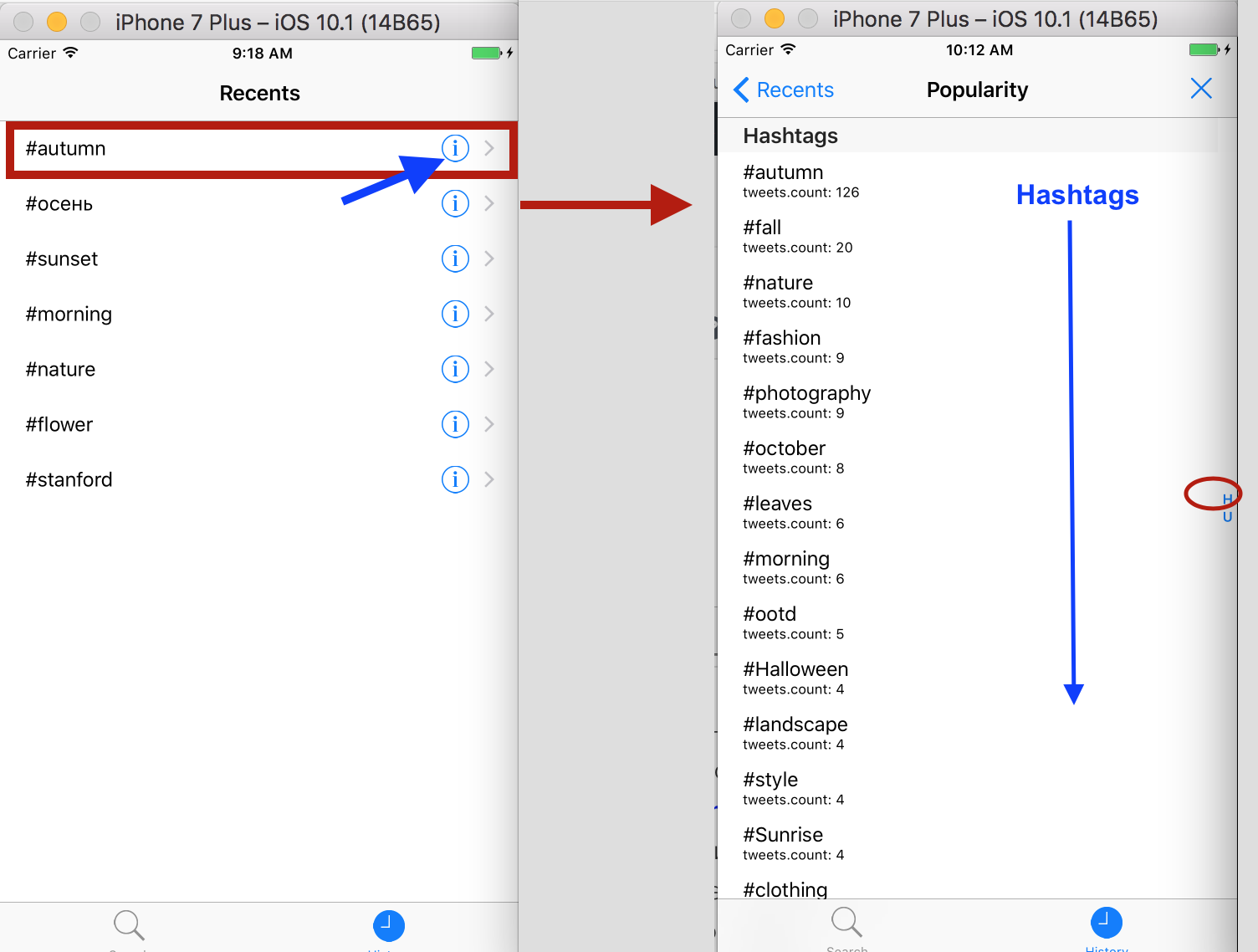
При нажатии кнопки с буквой i в кружочке мы создаем Таблицу Популярности меншенов во всех твитах, возвращенных при поиске по данной поисковой строке (в нашем случае #autumn). Эта таблица должна подчиняться определенным правилам:
- она должна быть отсортирована в порядке популярности от наиболее популярных меншенов в верху таблицы к менее популярным внизу,
- если два (или больше) меншенов имеют ту же самую популярность, эти меншены появляются в таблице в алфавитном порядке,
- каждая строка в таблице показывает не только меншен, но также и сколько раз этот меншен упоминался в твитах, найденных при задании этой поисковой строки,
- в таблицу не помещаются меншены, которые упоминаются лишь один раз,
- не должно быть дублирования меншенов в твитах, которые выбираются более одного раза.
- разделите вашу Таблицу Популярности меншенов на две Секции: хэштеги (Hashtags) и пользователи (Users).
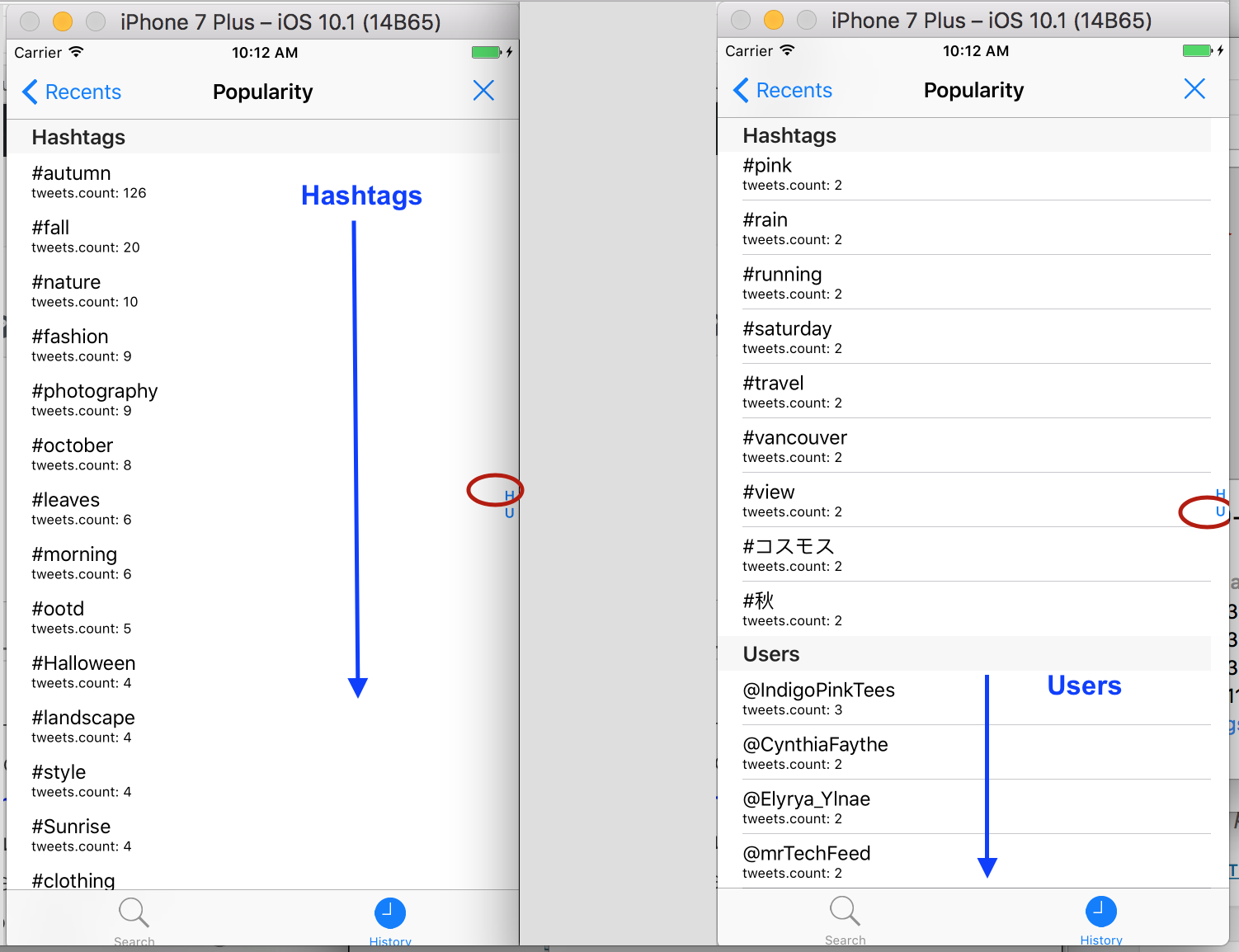
Индекс «H» соответствует хэштегам Hashtags, а индекс «U» — пользователям Users.
От нас не требуется разрушать функционирование остальной части приложения Smashtag. Нет требований в Задании 5 преобразования уже существующих MVC из предыдущего Задания, в MVC, использующие Core Data, это касается только нового MVC — Таблицы Популярности меншенов. Конечно, нам придется модифицировать уже существующий код для запоминания в Core Data данных, которые мы будем использовать в Таблице Популярности.
Пункт 1 обязательный
В вашей закладке Recent Searches (последние строки поиска), добавьте кнопку Detail Disclosure к каждой строке. При ее нажатии вы должны “переезжать” (segue) на новый MVC с таблицей, которая показывает список всех меншенов с пользователями (users) и хэштегами (hashtags) во всех твитах, когда-либо выбранных с использованием поискового текста (search term) в этой строке таблицы. Предполагается, что меншены должны быть уникальны и нечувствительны к регистру.
Сначала сделаем всю необходимую подготовку на storyboard.
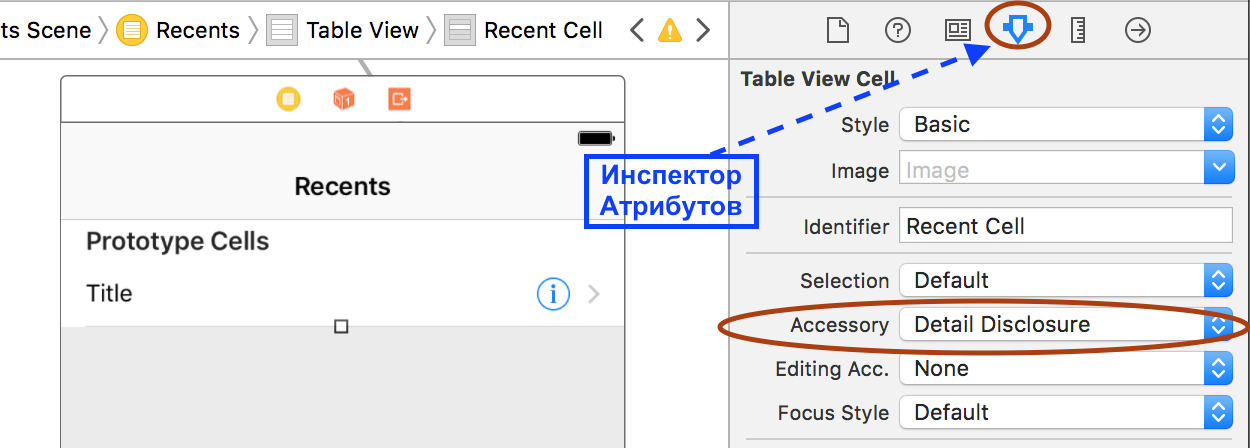
- Добавим кнопку Detail Disclosure (с буквой i в кружочке) к каждой строке экранного фрагмента Recents:
2. Создадим новый MVC типа Table View Controller, как всегда вытянув его из Палитры Объектов.
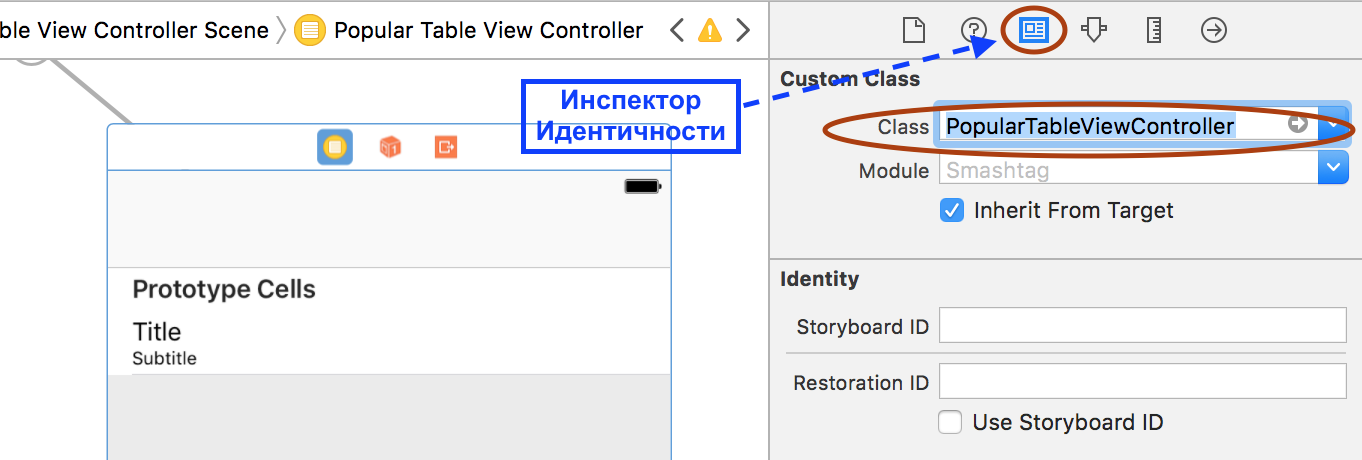
3. Создадим пользовательский класс для нового MVC c именем PopularTableViewController с superclass UITableViewController.
4. Установим пользовательский класс PopularTableViewController для нового MVC.
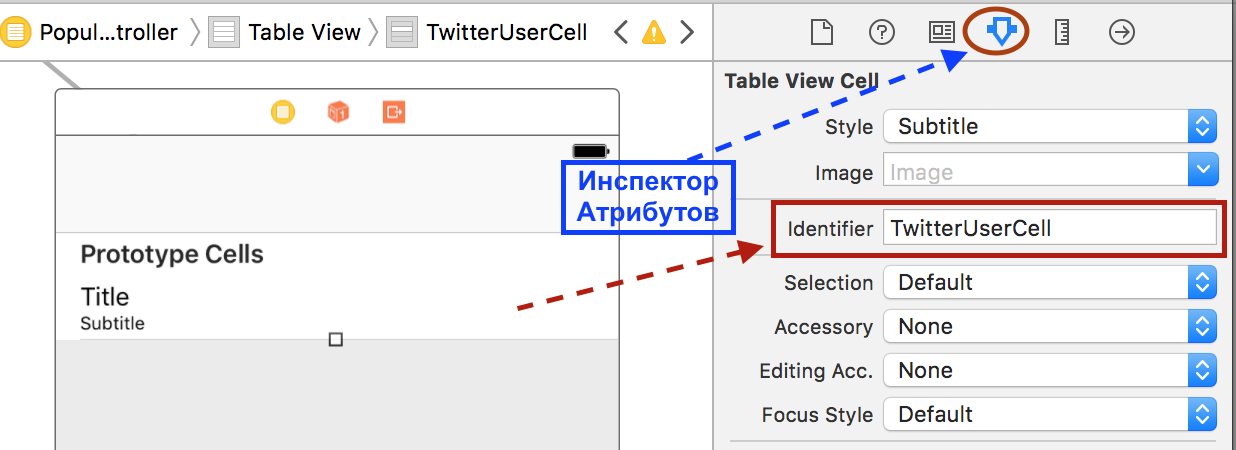
5. Конфигурируем ячейку в новом MVC. Это будет стандартная ячейка стиля Subtitle с идентификатором TwitterUserCell:
6. Создаем с помощью CTRL-перетягивания segue от экранного фрагмента Recents к новому MVC. Это будет Show segue, но он будет идти не непосредственно от строки в таблице, а от кнопки с буквой i в кружочке. Мы знаем, что от строки можно создавать два segues. Один у нас уже есть. Давайте создадим второй. Начинаем мы как всегда с CTRL-перетягивания от ячейки, а вот когда мы отпускаем клавишу CTRL, то нам будут предлагаться обычные segue от строки в разделе «Selection Segue» и от кнопки с буквой i в кружочке в разделе «Accessory Action«.
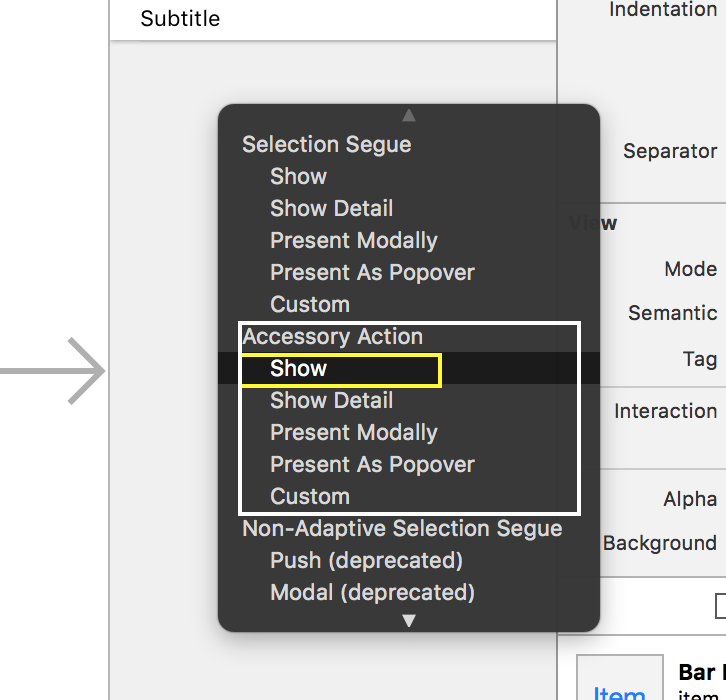
Мы выбираем Show в разделе «Accessory Action«. Дадим имя этому segue «ShowPopularMensions» и зафиксируем это в классе RecentsTableViewController:

Вернемся к классу PopularTableViewController, обслуживающему наш новый MVC, удалим весь пришедший с шаблоном код и подумаем, что будет Моделью этого MVC.
Пункт 2 обязательный
Таблица популярности меншенов во всех твитах, возвращенных при поиске по данной поисковой строке, должна быть отсортирована в порядке популярности от наиболее популярных меншенов в верху таблицы к менее популярным внизу.
Пункт 3 обязательный
Если два (или больше) меншенов имеют ту же самую популярность, эти меншены должны появляться в таблице в алфавитном порядке.
Пункт 4 обязательный
Каждая строка в таблице должна показывать не только меншен, но и число раз, сколько этот меншен упоминался в твитах, найденных при задании этого поискового терма.
Пункт 5 обязательный
Для того чтобы меншен относился к “популярным”, он должен упоминаться более 1 раза.
Пункт 6 обязательный
Однажды посчитанные в определенном твите меншены не должны вновь участвовать в подсчете количества упоминаний для того же самого твита, если при выборке этот твит появляется вновь. Другими словами, не должно быть быть дублирования меншенов в твитах, которые выбираются более одного раза.
Пункт 7 обязательный
Все данные, которые проходят через новый MVC должны быть запомнены в Core Data (и должны постоянно сохраняться между запусками вашего приложенния).
Всякий раз, когда мы реализуем новый MVC, самая главная вещь, с которой вы должны начать, и профессор настаивал на этом в этом курсе, это Модель данного MVC. Вы должны понять, что делает этот MVC и какова его Модель.
В нашем случае Popular Table View Controller MVC берет некоторую поисковую строку в виде меншена типа #stanford, ищет и подсчитывает все меншены, связанные с выборкой твитов по этой поисковой строке.
Понятно, что очень важная часть этой Модели — mention, то есть строка поиска типа #stanford. Но другая действительно важная часть нашей Модели — это база данных Core Data. Без нее мы не сможем найти меншены, которые появились в твитах, использующих строку mention. Так что, другая часть Модели — container типа NSPersistentContainer. Он будет Optional, но если он равен nil, то у меня будет пустая таблица. По умолчанию мы берем container из AppDelegate.
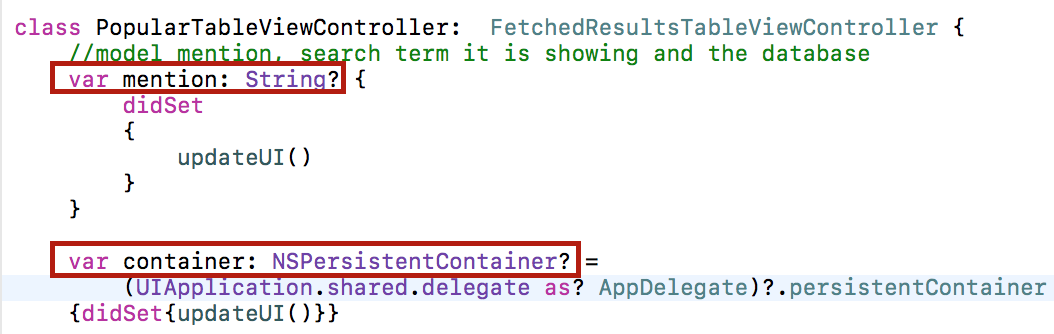
При изменении базы данных или поисковой строки мы будем обновлять пользовательский интерфейс с помощью метода updateUI(), в котором и будем производить запись данных в Core Data.
Прежде чем использовать Core Data, мы должны создать схему базы данных и разместить там данные согласно изобретенной нами схемы.
Все это мы должны делать там, где мы получаем выбранные твиты по поисковой строке, то есть в классе TweetTableViewController, в этом же классе находится поисковая строка в виде переменной searchText.
Далее действуем так, как показано в демонстрационном примере на Лекции 11.
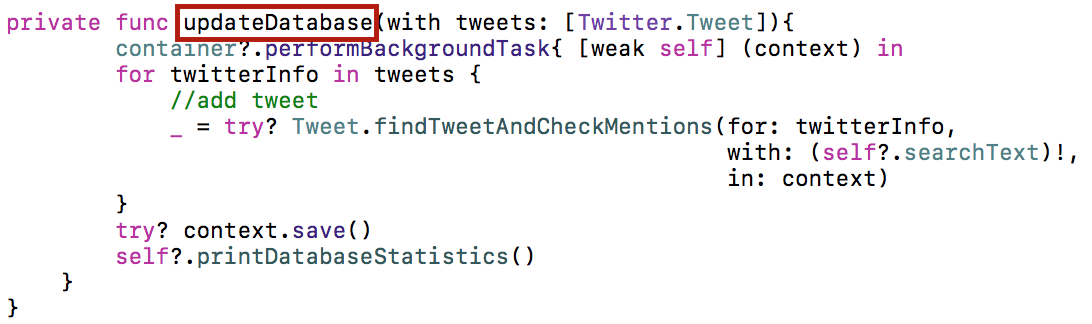
Для работы с базой данных мы создаем subclass SmashTweetTableViewController класса TweetTableViewController. В нем мы переопределяем метод insertTweets, в котором обновляем базу данных с помощью метода updateDatabase:
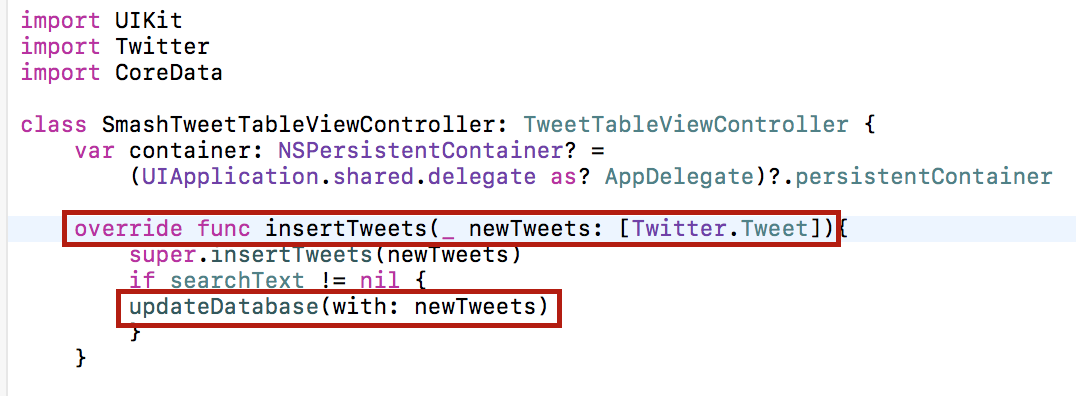
Для метода updateDatabase нужна Модель Данных или схема базы данных. Будем отталкиваться от того, как должна выглядеть таблица меншенов в этой задаче и тем, что мы должны сортировать эту таблицу по числу count твитов, в которых он упоминается.
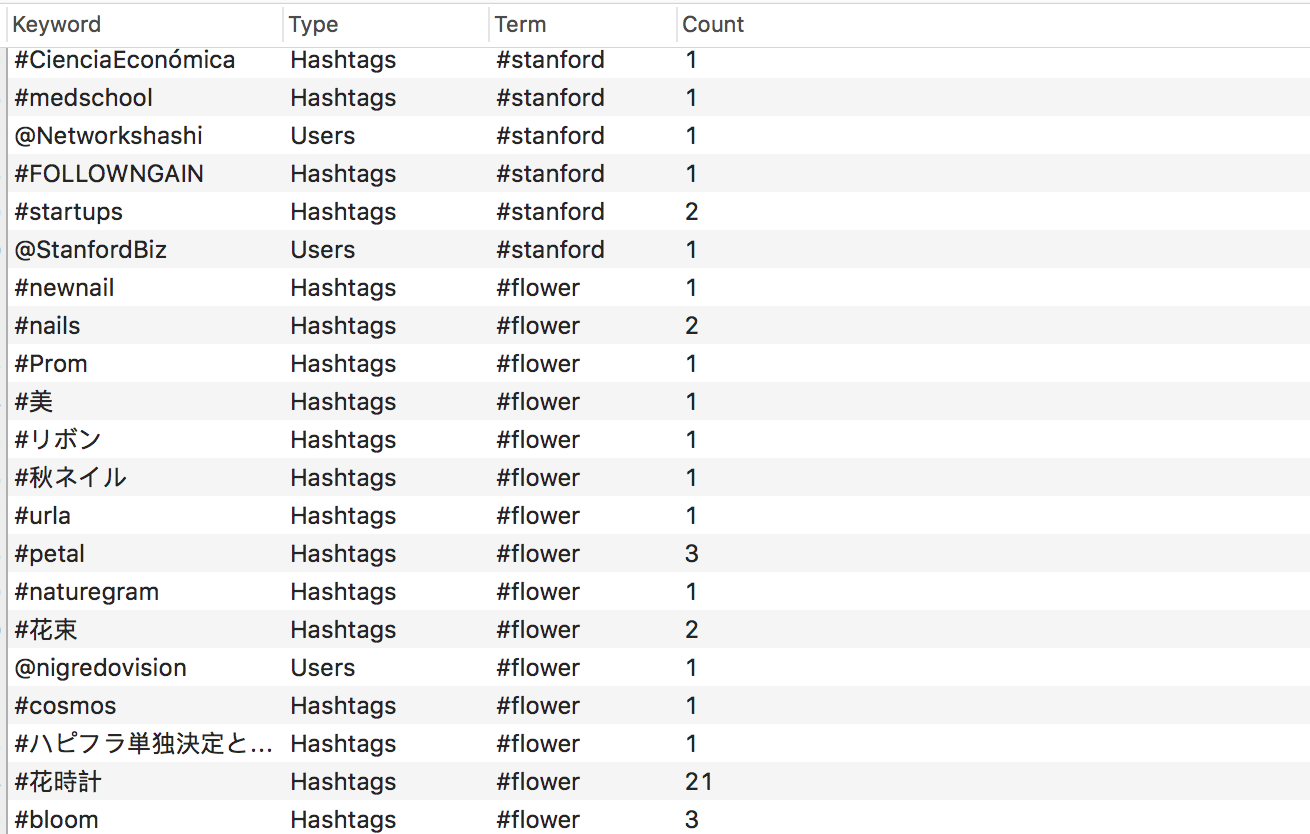
Я приведу Модель Данных сразу в готовом виде и объясню, почему она именно такая:
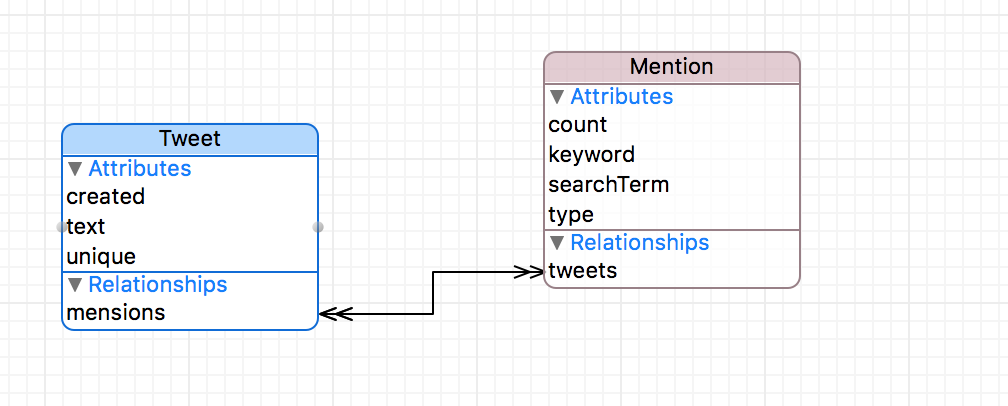
У нас в схеме базы данных будет две Сущности: твит Tweet и меншен Mention.
Сущность Tweet нам уже знакома из демонстрационного примера. Сущность Mention представлена своими Атрибутами keyword, count и type («Нashtags'» или «Users»), кроме того, каждый меншен строго «маркируется» только одним поисковым термом searchTerm. Ключевыми Атрибутами, определяющими уникальность Сущности Mention, являются keyword и searchTerm. Только в этом случае мы сможем корректно посчитать требуемое нам количество твитов count, в которых упоминается этот меншен при использовании строки выбора searchTerm.
Сущности Tweet и Mention имеют Взаимосвязь типа «To Many» с обоих сторон, так как понятно, что один и тот же твит может оказаться в выборках для разных поисковых строк. Взаимосвязь tweets в Сущности Mention показывает, какие твиты участвовали в формировании Атрибута count, и не учитывать их повторно. Это очень важная взаимосвязь, с ее помощью мы можем контролировать повторно выбранные твиты для определенного меншена и не обрабатывать их, если они уже присутствуют в базе данных. Таким образом удается избегать дублирования.
Для создания subclasses для наших Сущностей Tweet и Mention, как показано на Лекции 11, мы выбираем в поле CodeGen в Инспекторе Модели Данных опцию Category/Extension, которая создаст только расширения extension для наших классов, добавив туда все переменные vars.
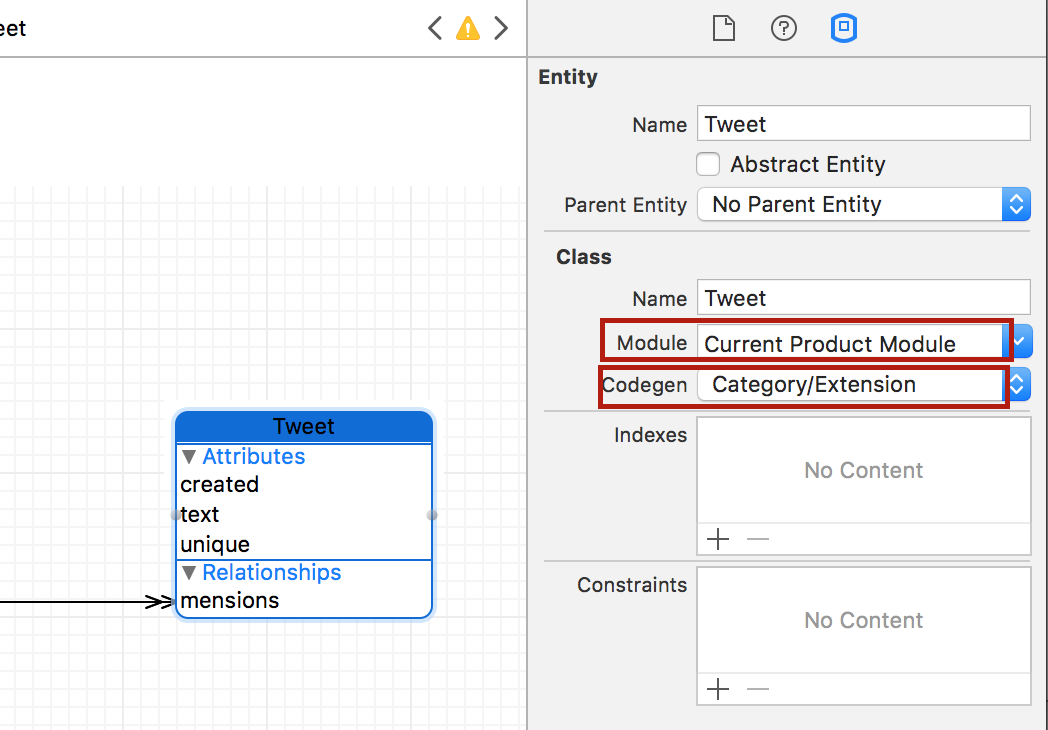
Необходимо изменить опцию в поле Module на Current Product Module, что будет означать Smashtag.Tweet. Не забывайте об этом.
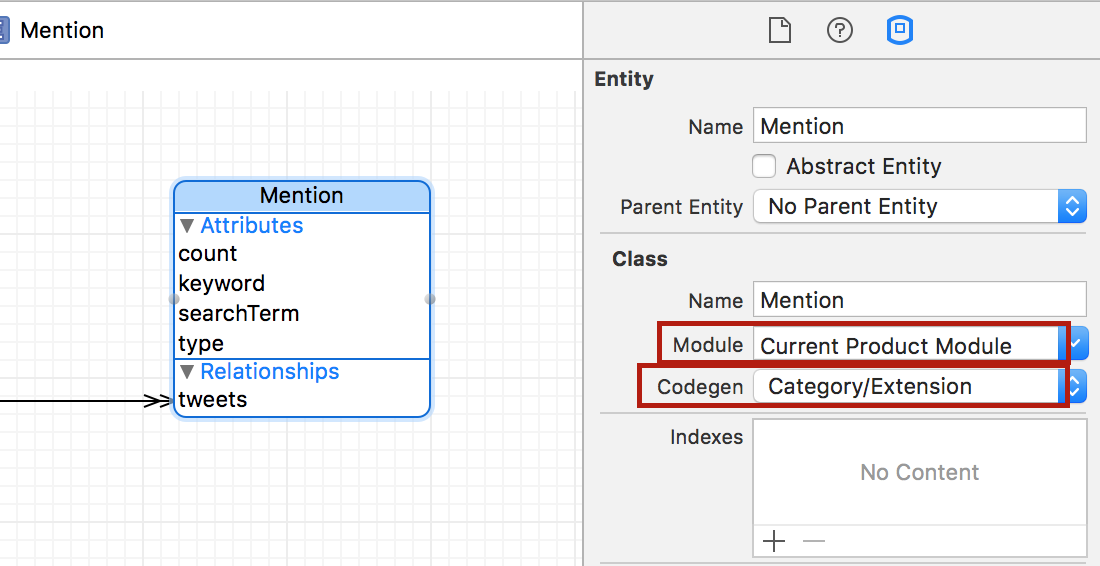
Необходимо изменить опцию в поле Module на Current Product Module, что будет означать Smashtag.Mention.
А мы сами должны написать основные классы Tweet и Mention.
Как обычно для создания класса мы используем меню File ->New -> File, наш случай ничем не отличается от остальных.
В классе Tweet мы разместим привычный нам из Лекции 11 метод findOrCreatTweet , который будет возвращать твит Tweet, новый или найденный:

В классе Mention мы разместим аналогичный метод findOrCreatMention, который будет возвращать меншен Mention, новый или найденный:
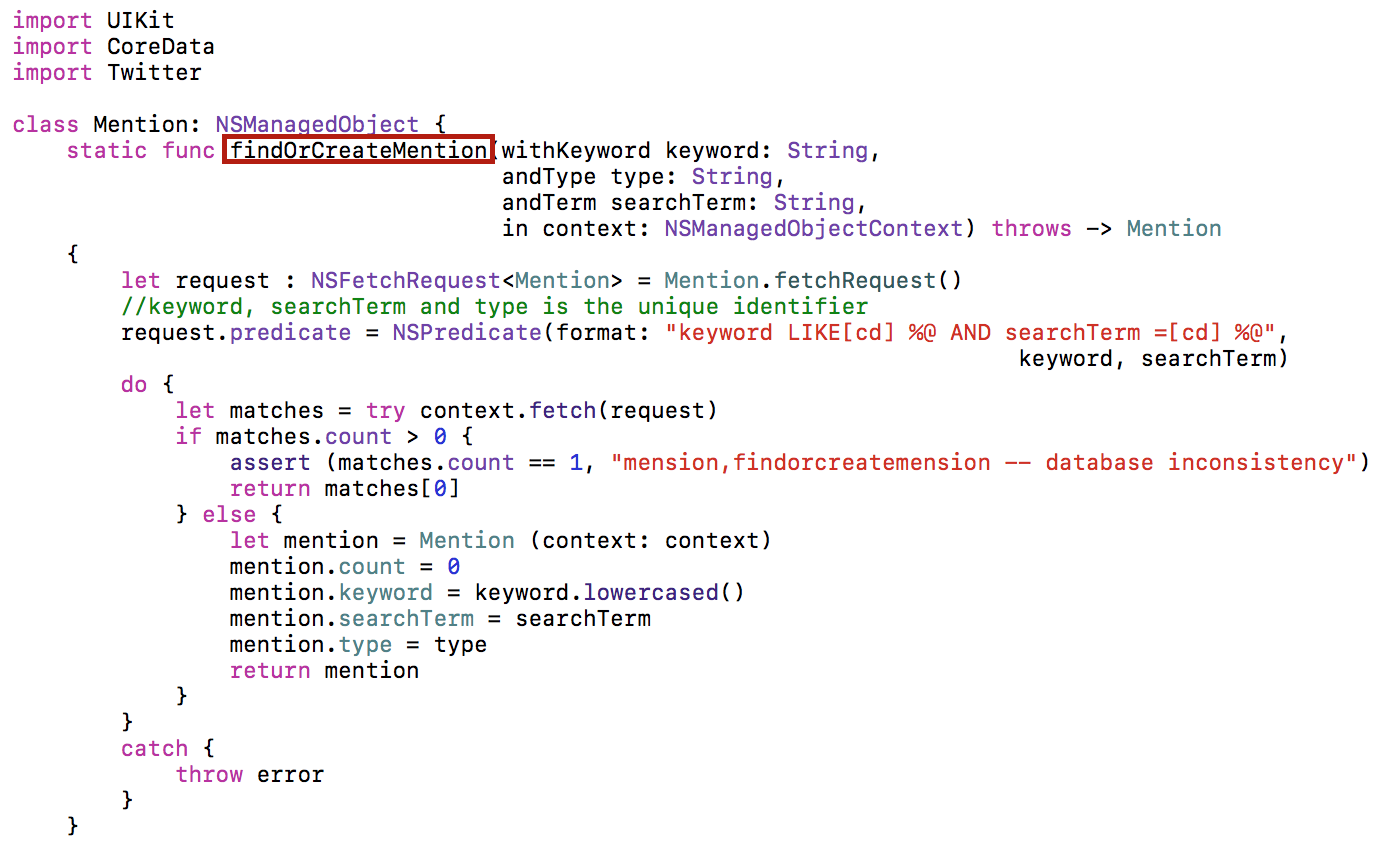
В классе Mention мы разместим также метод checkMention, который будет проверять, учтен ли данный твит tweet в определенном меншене, который характеризуется атрибутом keyword и searchTerm, и если не учтен, то добавит 1 в атрибут count:
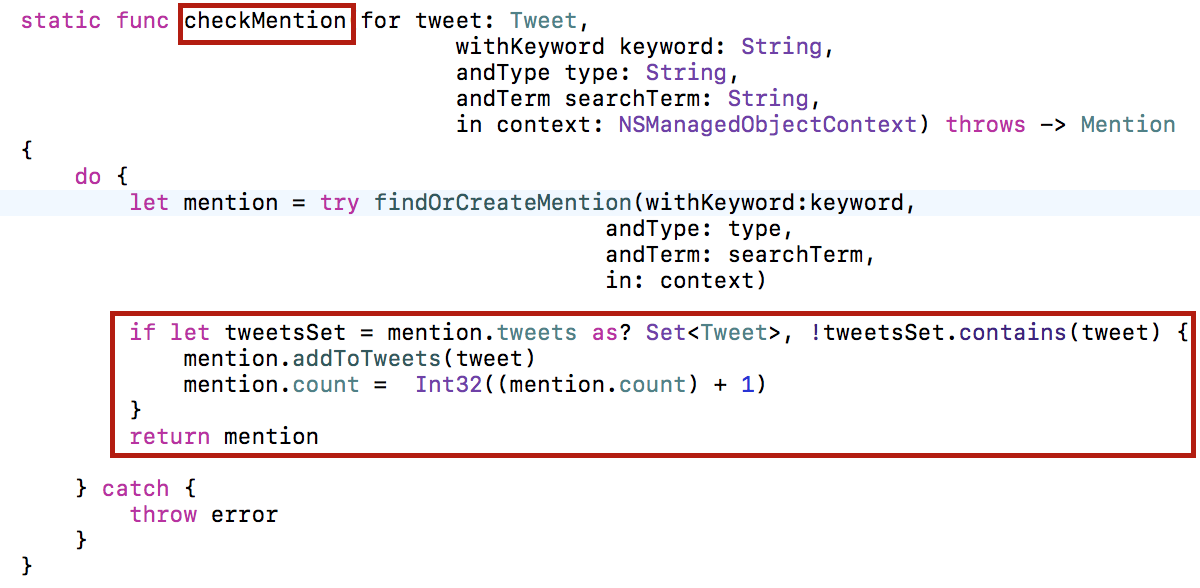
В классе Tweet мы разместим метод findTweetAndCheckMentions, который будет возвращать твит Tweet, новый или найденный, и учтенный в меншенах:
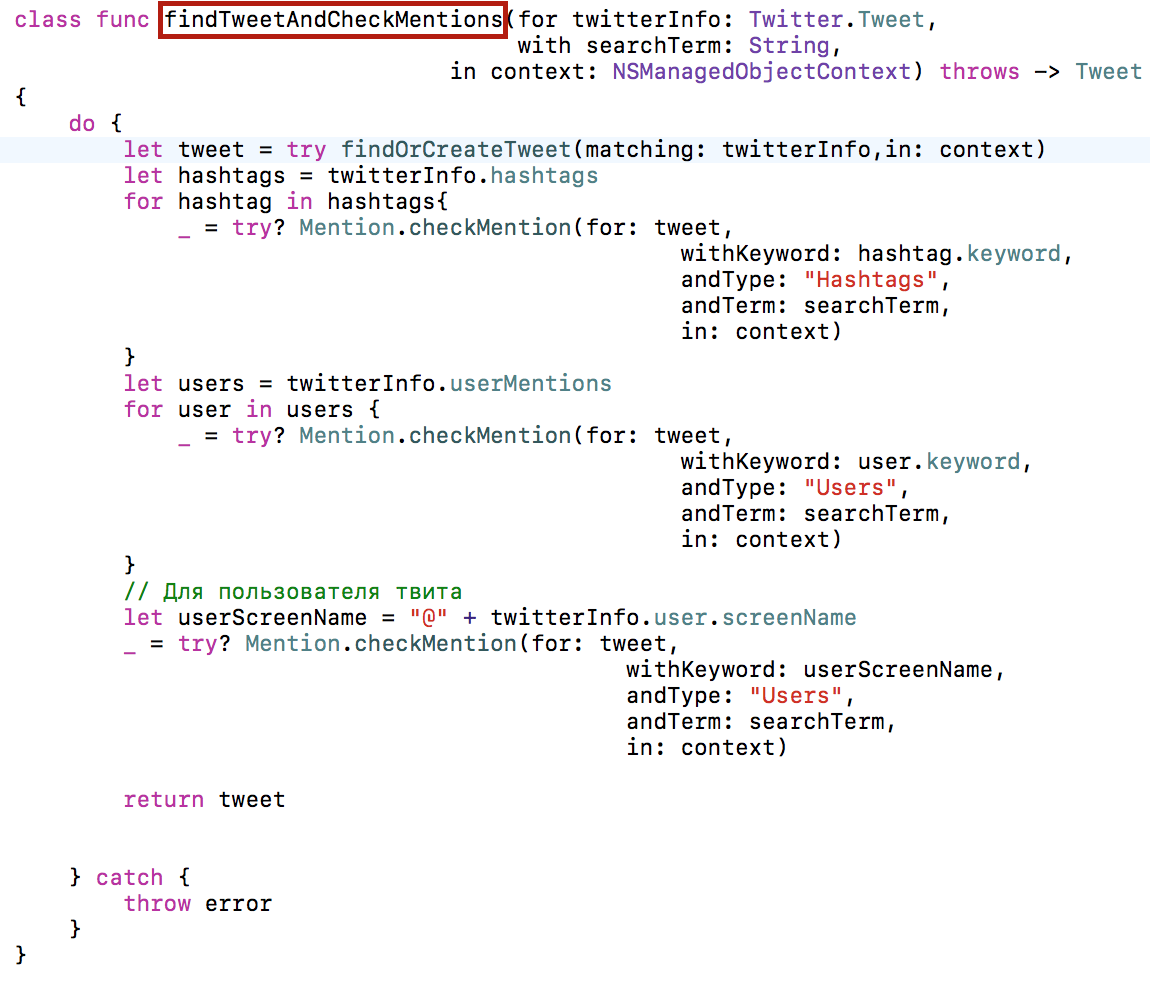
Возвращаемся к методу updateDatabase () в классе SmashTweetTableViewController. Мы будем использовать метод findTweetAndCheckMentions класса Tweet, который принимает решение о размещении данных конкретного твита tweeterInfo, полученного с сервера Twitter, и текущей поисковой строкой searchTerm, в базе данных.
Также как и в демонстрационном примере Лекции 11, мы создадим метод печати краткой информации о содержимом базы данных printDatabaseStatistics():
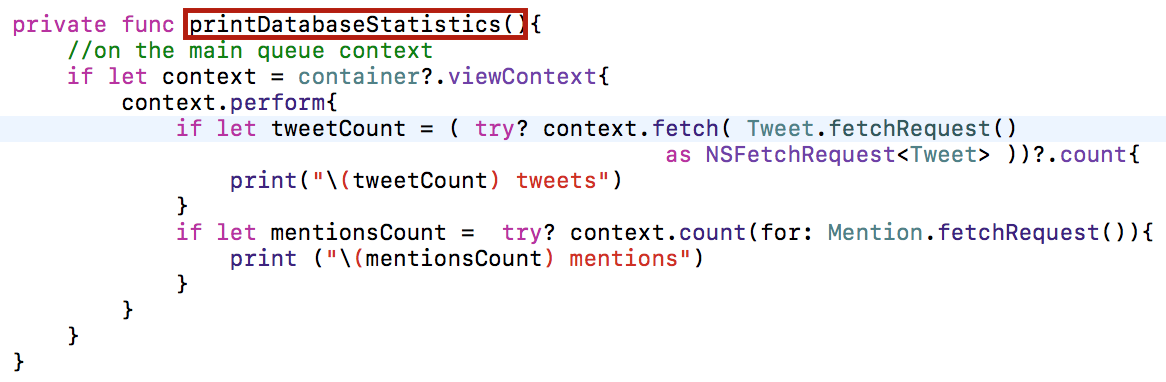
Итак, наши данные записаны в базу данных и сохранены.
Мы можем перейти ко второй части нашего приложения, а именно к наполнению данными нашего нового MVC.
Пункт 8 обязательный
Контент вашего нового MVC должен управляться NSFetchedResultsController (вы можете использовать FetchedResultsTableViewController в качестве superclass для Controller вашего нового MVC, если хотите).
Пункт 9 обязательный
Не разрушайте функционирования остальной части приложения Smashtag. Нет требований преобразования уже существующих MVC из предыдущего Задания, в MVC, использующие Core Data, только новый MVC. Конечно, вам придется модифицировать уже существующий код для запоминания данных, которые вы собираетесь использовать в новом MVC.
.
Класс PopularTableViewController, обслуживающий наш новый MVC, делаем subclass класса FetchedResultsTableViewController согласно технологии, представленной на Лекции 11.
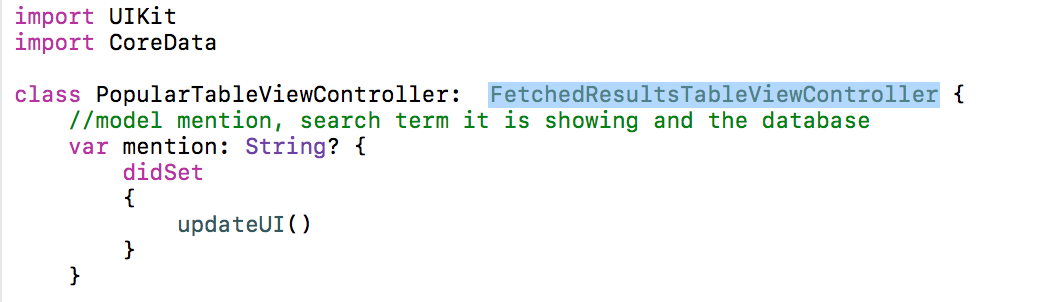
Об этом классе подробно рассказывается на Лекции 11.
В методе updateUI() мы создаем fetchResultsController помощью инициализатора NSFetchedResultsController<Mention>, предварительно определив запрос request, его дескрипторы сортировки sortDescriptors и очень простой предикат predicate:
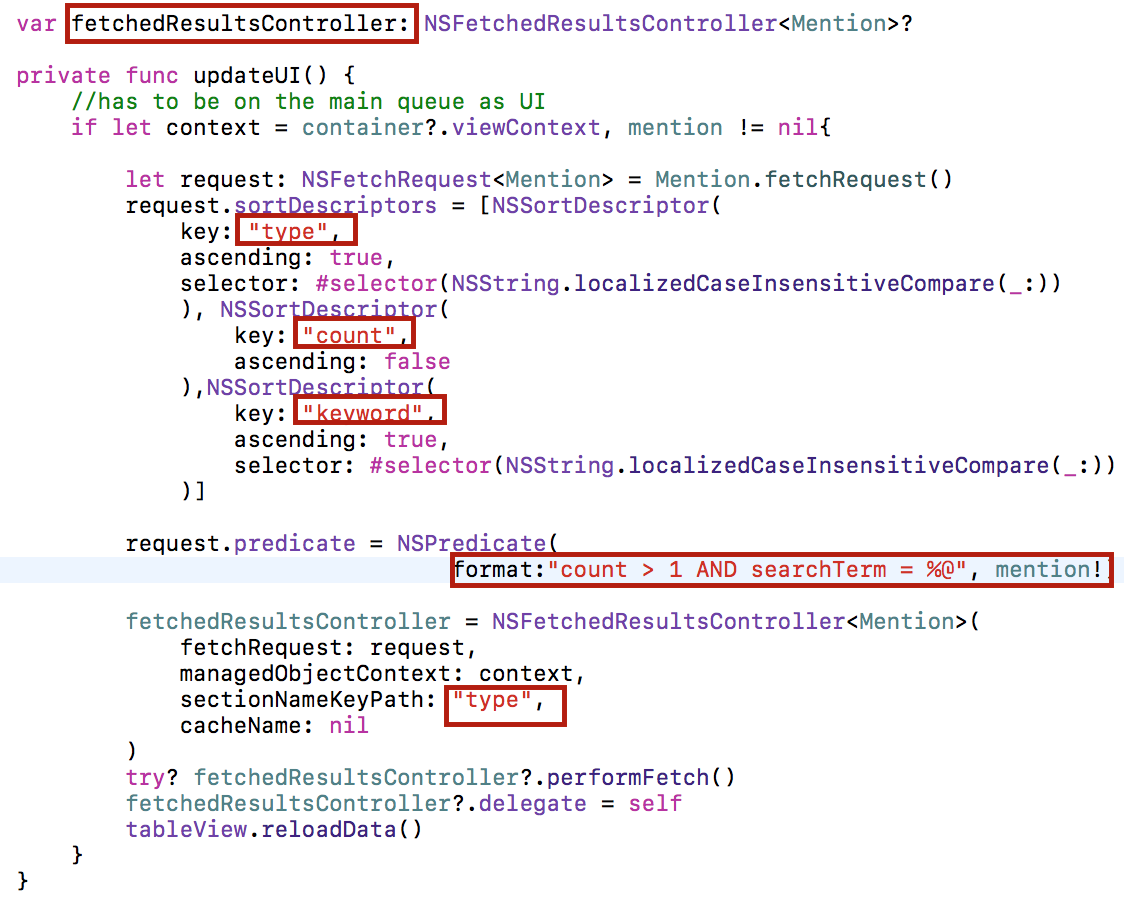
Мы выбираем меншены, относящиеся к поисковой строке mention, которая является Моделью данного MVC. Сортируем результаты сначала по типу меншена type («Hashtags» или «Users«), затем по количеству твитов count, в которых он упоминался, и по имена меншена keyword. В нашей таблице будут Секции, организованные по типу меншена type, поэтому этот атрибут стоит первым в массиве дескрипторов сортировки.
Итак, у нас есть эта переменная var с именем fetchedResultsController, как мы будем использовать ее во всех этих методах UITableViewDataSource?
Мы можем разместить код для них всех, но, вы знаете, что все они имеют ВСЕГДА один и тот же код, потому что fetchedResultsController ВСЕГДА отвечает на эти вопросы в точности одним и тем же способом.
Вы можете скопировать и вставить этот код из того, что вы уже делали, или вы можете использовать этот небольшой прекрасный код, который создал профессор Пол Хэгерти для вас. Я перетягиваю файл UITableViewControllerSource+NSFetchedResultsController.swift >в мой проект, при этом используя, конечно, опцию “Copy item…”. Bот как выглядит код:

Это расширение extension, с помощью которого я расширяю свой класс. В нашем случае это PopularTableViewController класс. В этом расширении extension добавлены все методы UITableViewDataSource. Видите? Они все реализованы с использованием fetchResultsController.
Это расширение extension не будет компилироваться, если у вас нет fetchResultsController, потому что сами расширения extension не могут добавлять никакого хранилища, следовательно, у вас должно быть хранилище в вашем собственном классе, и в этом классе у нас действительно есть fetchResultsController.
Мне осталось реализовать метод cellForRowAt в классе PopularTableViewController, и я смогу запустить приложение. Для этого нужно установить reuseIdentifier и сконфигурировать ячейку cell:
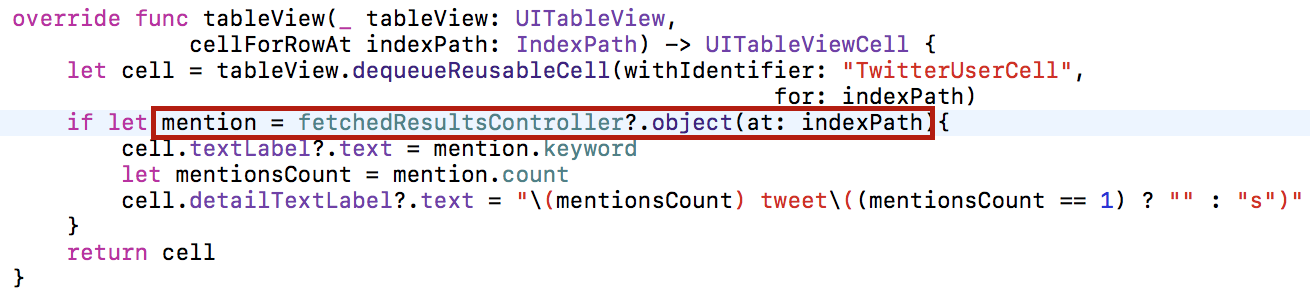
Запускаем приложение.
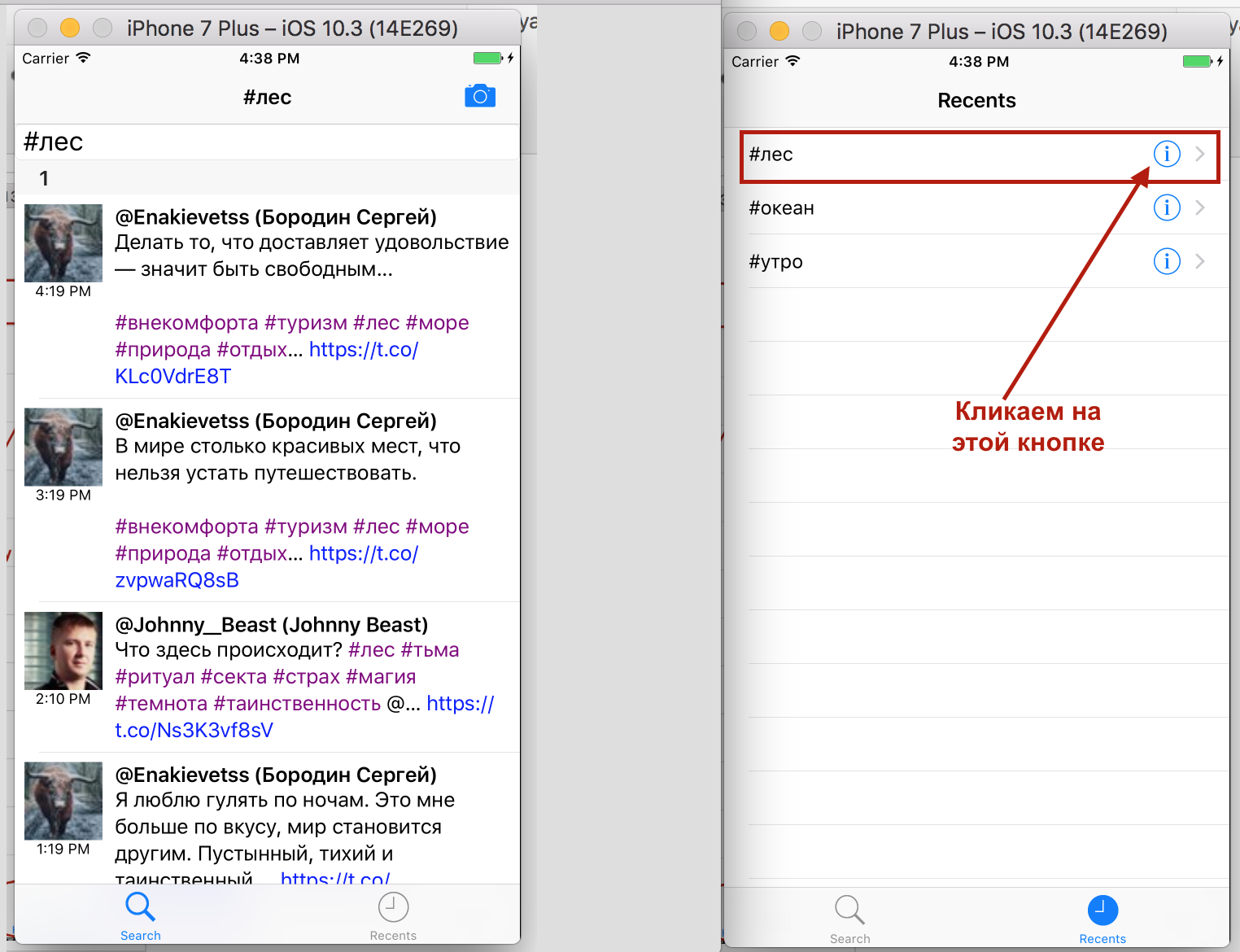
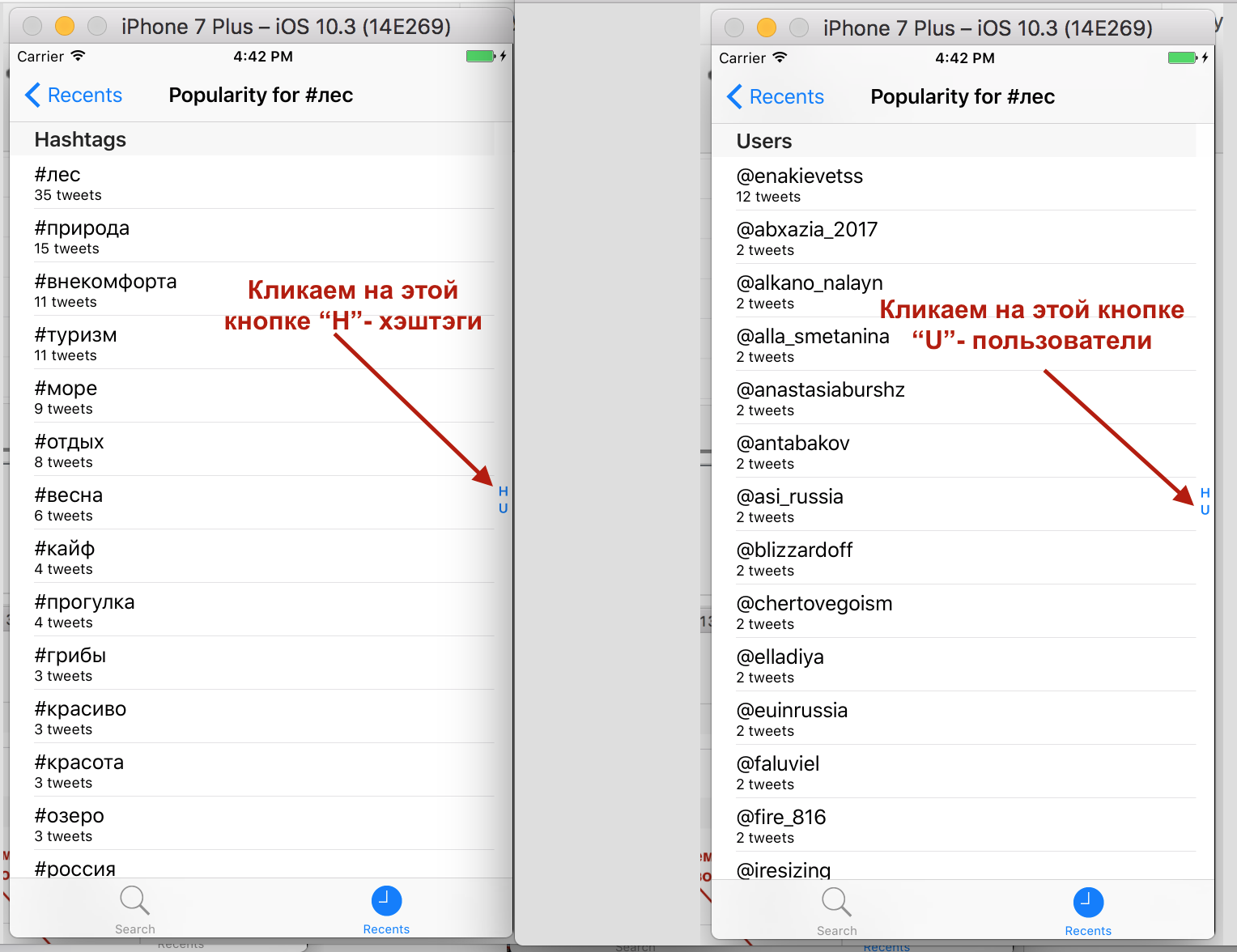
Все работает прекрасно.
Пункт 10 обязательный
В любое время вы НЕ должны блокировать main thread в вашем приложении. Вы можете предположить, что любые вызовы Core Data не займут слишком много времени, чтобы блокировать main thread (к счастью, вы сконструировали схему базы данных таким образом, что это действительно справедливо даже при загрузке большого числа твитов).
Код полностью настроен на работу приложения в многопоточной среде благодаря «обертывания» всех действий с базой данных в методы performBlock и performBlockAndWait и любой момент может быть переведен на контекст, функционирующий не на main queue.
Пункт 11 обязательный
Ваше приложение должно работать правильно как в портретном, так и в ландшафтном режимах на любом iPhone (это приложение только для iPhone).
Пункт 12 обязательный
Вы должны получить приложение, которое работает на реальном приборе, а не только на Симуляторе.
Все это выполнено.
Пункт 1 дополнительный
Разделите вашу таблицу с популярностью меншенов на две Секции: хэштеги (Hashtags) и пользователи (Users). И опять, при правильной схеме базы данных, этот пункт может быть реализован несколькими (может быть, двумя) строками кода.
Выполнено.
Пункт 2 дополнительный
Загрузка большого количества данных путем запроса существующего в базе данных экземпляра Сущности, а затем вставки его , если этот экземпляр не найден, снова и снова, по одному ( как мы делали на лекции), может оказаться очень не производительной. Ваше приложение можно улучшить и сделать его более эффективным по производительности, если проверять одним запросом существование в базе данных целой кучи объектов, которые мы хотим разместить, а затем создавать только те, которые там отсутствуют. Предикат с оператором IN может понадобиться в этом случае.
Создадим в классе Tweet метод, который будет обрабатывать сразу весь массив новых твитов [Twitter.Tweet].
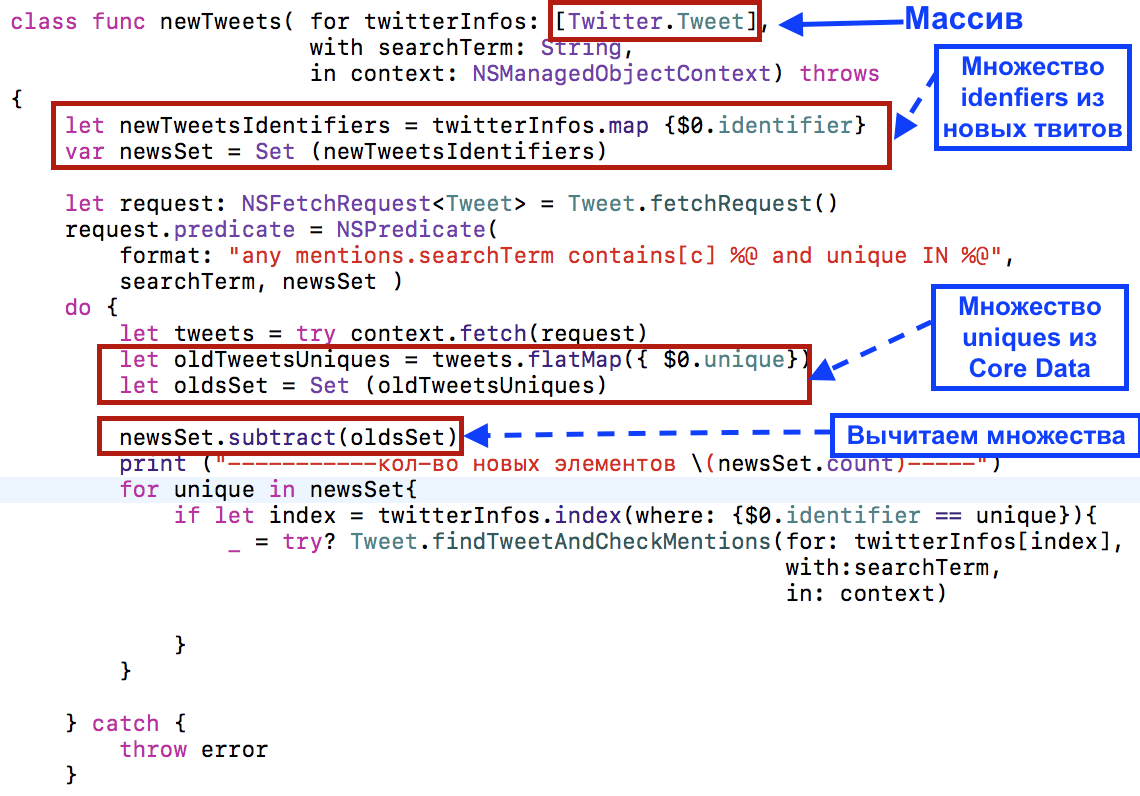
Идея этого метода состоит в том, что мы сначала определяем множество newsSet, состоящее из identifiers новых твитов, полученных с сервера Twitter, затем формируем запрос с предикатом, содержащим оператор IN, для поиска в базе данных сразу всех твитов, входящих в множество newsSet, и учтенных там с поисковой строкой searchTerm:

В результате мы получаем массив твитов tweets, уже содержащихся в базе данных, который мы превращает в множество атрибутов unique для этих твитов:

А затем вычитаем из множества newsSet identifiers новых твитов множество oldsSet твитов, находящихся в базе данных, и, таким образом получаем уточненное множество newsSet новых твитов, которых еще нет в базе данных и которые нужно записать:

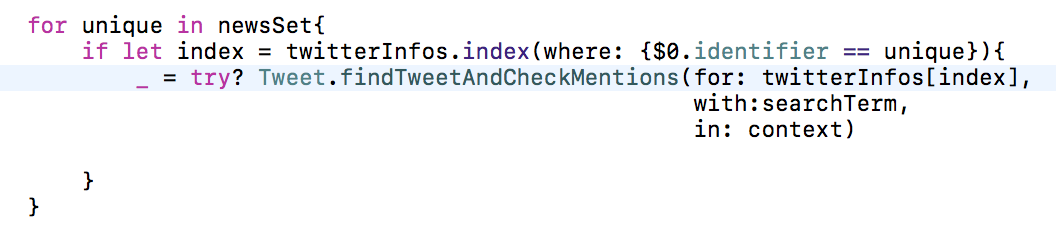
Далее мы записываем эти «действительно новые» твиты в базу данных по одному:
Естественно в методе updateDatabase () в классе SmashTweetTableViewController мы будем использовать более эффективный метод newTweets класса Tweet, а старый код, где производится загрузка твитов по одному, для сравнения я оставлю закомментированным:
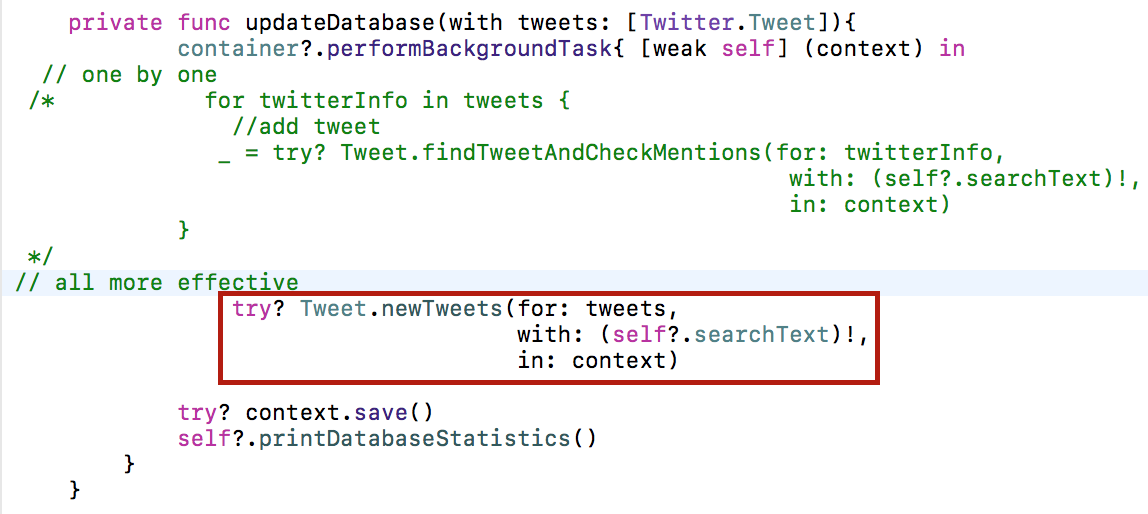
Код находится на Github.
Пункт 3 дополнительный
Вам не требуется нигде что-либо уничтожать из базы данных, тем не менее, нам необходима информация лишь о наиболее поздних поисках в Twitter, так что со временем у нас напрасно занимается большой объем дискового пространства. Заставьте ваше приложение удалять из базы данных объекты, которые больше не представляют интереса (то есть доступ к этим данным не будет осуществляться в вашем UI) с тем, чтобы поддерживать регулируемый размер базы данных. Вы должны самостоятельно решить, когда наступает подходящее время для удаления уже неиспользуемых данных.
Решение для дополнительного пункта 3 будет находится в посте «Задание 5 cs193p Winter 2017 Smashtag Mentions Popularity. Решение дополнительного пункта 3 (удаление старой информации из Core Data)».
Здравствуйте. Еще раз спасибо за материал. Мне кажется, здесь в посте пропущена часть текста. После картинки с моделью базы данных и текста «Я приведу Модель Данных сразу в готовом виде и объясню, почему она именно такая:» следующий абзац начинается с оборванного предложения, и решение затем сразу перескакивает на пункт 10, пропуская пункты 8 и 9.
Спасибо. Поправила. Действительно, огромный кусок поста не записался.
Пытаюсь решить задание дальше и разобраться в CoreData. Мне не очень нравятся атрибуты mention под названием count и search term, потому что такой способ хранения создает много дубликатов mention с одинаковым keyword, различающихся лишь словом поиска. Также это немного нарушает логику самой базы данных, потому что по идее Tweet должен «знать» про свои Mention без учета поискового слова, по которому они были найдены, а так выходит, что tweet имеет несколько одинаковых mention от разных поисковых запросов. Текущее задание это решит, но в дальнейшем при добавлении новых «фишек» может создать проблемы, как мне кажется, и придется переделывать базу данных.
Также я заметил, что у вас в некоторых методах есть лишние аргументы — тело метода findOrCreateTweet не использует аргумент searchString, а тело findOrCreateMention не использует tweet, вроде бы.
Я попробую решить это задание, используя 4 сущности в базе данных — tweet, mention, searchTerm и counter (counter считает количество mention для определенного searchTerm), только вот боюсь запутаться во отношениях между ними и запросах к базе. Но такой метод мне кажется более правильным, потому что он не дублирует mention для разных слов поиска.
Если вы внимательно слушали Лекцию 11, то наверно, поняли намеки профессора о том, что наша задача состоит в том, чтобы fetchResultsController использовал максимально простой запрос, и исходить следует из того, что вам нужно конкретно отобразить в данном MVC, имея ввиду еще и сортировку по полю count. Собственно ради сортировки по этому полю и весь сыр бор. Я понимаю ваше желание привести базу данных к 4-ой нормальной форме, но надо учитывать, что это все таки не реляционная база данных, а база объектов, и связь «many-to-many» отображается в виде множеств.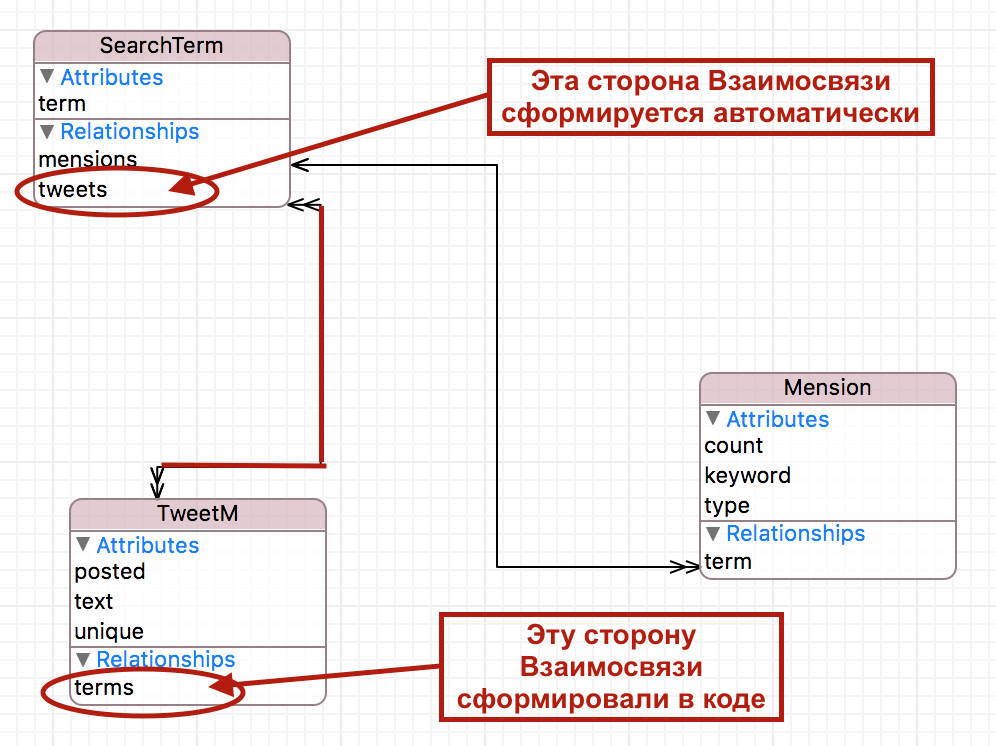
Кроме того, по-моему у вас неправильная трактовка, что такое count. Это НЕ «количество mention для определенного searchTerm», это количество ТВИТОВ, в которых упоминался данный mention при использовании данной поисковой строки searchTerm. Поэтому таблица называется таблицей популярности меншенов для конкретной поисковой строки. Поэтому выделять count в отдельную сущность в корне неправильно. Уникальность меншена характеризуется keyword + type и к ним жестко привязан count, который мы «расщепляем» по searchTerm. Таким образом, нужный нам count определяют 3 позиции: keyword + type + search. Как бы вы не разделяли эти Сущности, связь идет именно по этим полям и они все равно будут дублироваться, здесь нет суррогатных ключей.
В предыдущем курсе я пыталась выделить 3 Сущности:
Мой опыт отрицательный.Хотя все работало.
Можно посмотреть здесь https://bestkora.com/IosDeveloper/core-data-v-swift-3-v-ios-10/
Попробуйте, может быть у вас получится просто и хорошо. Это же интересно.
По поводу лишних аргументов — спасибо за замечание, хотела объединить два метода в один, лишний аргумент и остался. Исправим.
Да, спасибо за замечание, я неправильно сформулировал, что такое count.
В общем, у меня получилось создать базу данных. Пока не умею пользоваться github, поэтому залью скриншот: https://imgur.com/a/5AeeF
Получилось немного громоздко, но вроде всё работает.
updateDatabase добавляет searchTerm, настраивает связи твитов и меншенов. А каждый Counter считает количество пересечений сетов searchTerm.tweets и mention.tweets и сохраняет у себя значение.
Предикаты в итоге такие же простые.
Ну вот мы и добрались до самой главной вашей ошибки. У вас поле count перерассчитывается при добавлении каждого нового твита, да непросто перерассчитывается, а идет работа с множествами, что является очень затратной операцией и не на стороне базы данных, а прямо в приложении. Это очень неэффективно и этого никак нельзя допустить. Каждый новый твит должен приводить к очень простой и не затратной операции типа +1 в какое-то поле.
Именно поэтому было придумано поле count, чтобы его нельзя было рассчитывать каждый раз заново.
Конечно, надо посмотреть код записи в базу данных. Может там еще что-то интересное найдем. У вас есть Dropbox?
Кроме того, на вашей схеме дважды присутствуют множества tweets, mentions, counters, то есть идет удвоение информации.
Понял, да, неэффекитвно, но работа же в фоновом режиме идет, и перерасчитываются не все счетчики, а только для нужных пар searchTerm-mention. К тому же если вручную плюсовать, намного больше вероятность допустить ошибку, вдруг счетчик будет отличаться от реального состояния базы данных, как тогда исправлять? При перерасчете этого не произойдет.
А про удвоение информации немного не понял. То есть, если у меня есть общий запас твитов, например, и searchTerm имеет кусок этих твитов в качестве атрибута, и mention имеет кусок этих твитов в качестве аттрибута, то это удвоение информации? Там разве не указатели на объекты идут? Я просто плохо разбираюсь в этом, подскажите, пожалуйста. Вроде в лекции говорили, что core data оптимизирует все отношения и об этом беспокоиться не надо.
Никакой вероятности допустить ошибку при +1 по счетчику нет. У вас же жесткий алгоритм, ничего не следует бояться, и именно так следует поступать при накоплении информации в каком-то поле. А если это не счетчик и его нельзя пересчитывать? Заполнение базы данных НИКОГДА не выполняется перерасчетом. А если вы неправильно добавили твит или searchTerm? Почему вы в них так уверены? Заполнение базы данных перерасчетом — плохой стиль программирования.
Про удвоение точно не скажу, но дублирование одних и тех же данных точно есть. Но это неважно, ваша Схема базы данных вполне допустима, нужно только убрать перерасчет count.
В Лекции не говорилось об оптимизации взаимосвязей, там говорилось о том, что целостность базы данных поддерживается автоматически за счет того, что если вы заполнили один конец взаимосвязи, то другой конец этой же взаимосвязи заполнится автоматически, и не нужно его заполнять программным образом. Причем это не зависит от типа связи: с одной стороны может быть «To-One», а с другой стороны «To-Many».
В любом случае в Core Data не нужно бояться больших объемов данных, она сконструирована на супер эффективную обработку большого объема данных, даже если это изображения.
Понял, спасибо за критику.
Вот ссылка на дропбокс https://www.dropbox.com/sh/ivgeiwfticvgwtu/AAB-J5sLHid6mbWsIke9o3LCa?dl=0
Большое спасибо за ссылку. Я с удовольствием посмотрела ваше решение. Мне оно очень понравилось: все сделано очень грамотно, изобретательно и если я хотела бы «классику» реляционной базы данных, то именно ваше решение я бы и предпочла.
Но я пыталась найти место, где можно было бы все-таки накапливать counter, и, конечно, не нашла. Вы с самого начала жестко разделили все, что так связано в нашей задаче: Tweet и Mension — отдельно, и знать не знаю о searchTerm, searchTerm — отдельно и только тут вы вспоминаете о твитах Tweets и соответствующих им меншенах, которые уже не идентифицируются как новые или старые — они уже все в базе, их уже не разделить и +1 добавлять некуда.
Этим разделением вы обрекли себя на работу с множествами.
Ваше решение и мое решение практически находятся на разных полюсах. Их интересно сравнивать с точки зрения того, какое больше соответствует логики работы Core Data. Мой опыт интуитивно говорит о том, что в Core Data лучше жертвовать 4-ой нормальной формой и не плодить связи «Many-To-Many», но я в этом не уверена.
У нас private новый форум на Piazza https://piazza.com/. Можно поместить ваше туда.
Для регистрации вам необходимо пройти по ссылке:
http://piazza.com/moscow_physical_engineering_institute_bestkora.com/spring2017/mf141
код mf141
Может быть написать статью в habrahabr.ru?
И все таки есть эффективный способ решения вашего Задания 5.
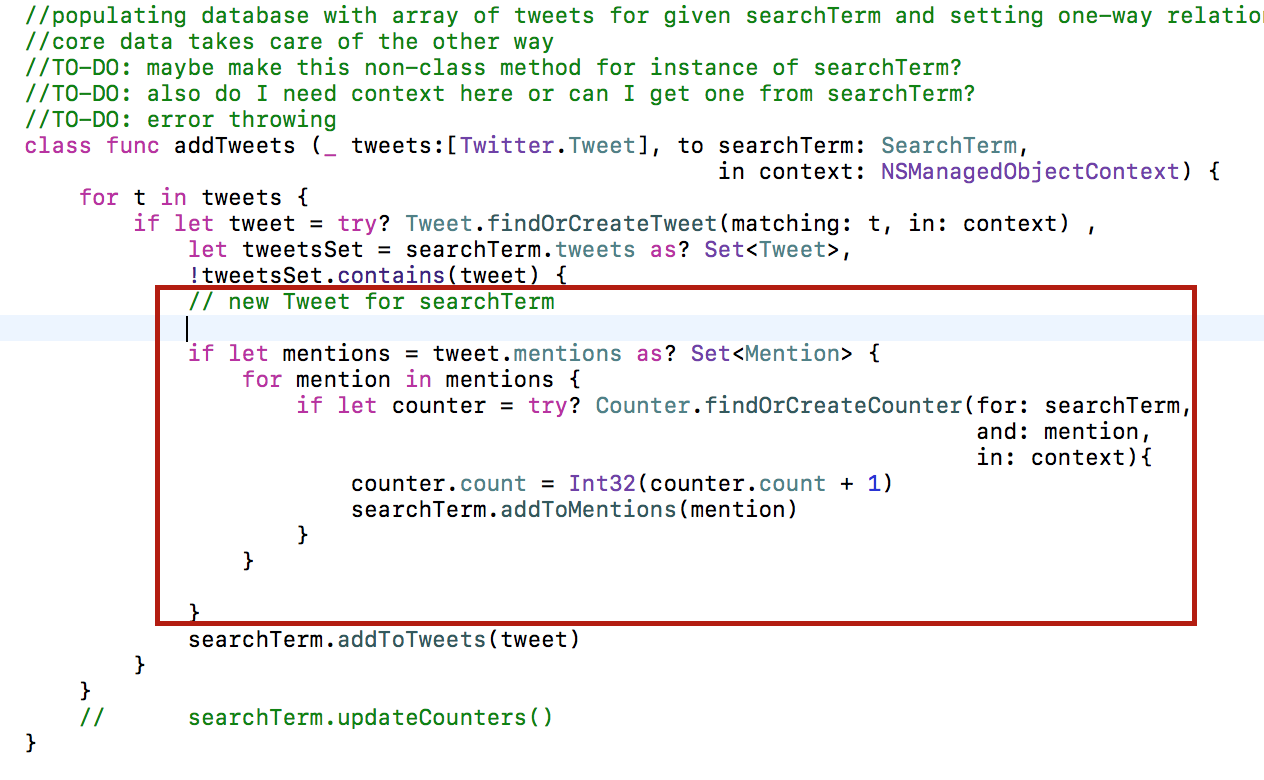
Нужно при добавлении каждого нового твита одновременно пересчитываю поле count.
Это метод
addTweets (_ tweets:[Twitter.Tweet], to searchTerm: SearchTerm, in context: NSManagedObjectContext)
Метод updateCounters уже не нужен и затратная работа с множества исключается.
Здорово!!
Прекрасное решение.
Действительно ваша схема позволяет ответить на многие вопросы.